
최근 ChatGPT의 등장으로 LLM에 대한 관심이 커지고 있습니다.
하지만 써보신 분들은 아시겠지만, 분명히 LLM도 한계점이 존재합니다.
예를 들어,
최신 정보 반영이 안되어 있다거나,
특정 기업 내에서 쓰는 비밀 문서 등
ChatGPT가 답변할 수 없는 부분도 있습니다.
그렇다면 이 정보를 넣기 위해 큰 모델을 다시 학습시켜야할까요?
아뇨! 꼭 그럴 필요는 없습니다.
관련된 문서를 프롬프트로 같이 넣어줌으로써 ChatGPT가 이를 이해하고, 답변해 줄 수 있습니다.
이것이 바로 RAG의 개념입니다.
ChatGPT에게 관련 문서를 던져주면서 "이게 관련 정보니까 내가 묻는말에 답해!"라고 하는 것과 같습니다.
그럼 이번 포스팅에서 더 자세히 알아볼게요!
더 나아가 실습까지 할 예정이니 끝까지 봐주시면 더 좋겠습니다.

RAG란?
RAG는 Retrieval Augmented Generation이라는 이름에서부터 알 수 있듯이, 관련된 정보를 검색하여 먼저 찾고, 이를 LLM에 같이 넣어 최종 답변을 생성하는 하나의 파이프라인입니다. 간단히 말씀드리자면, 검색 기반의 생성이라고 할 수 있습니다.
더 이해하시기 쉽게 플로우를 그려드릴게요!
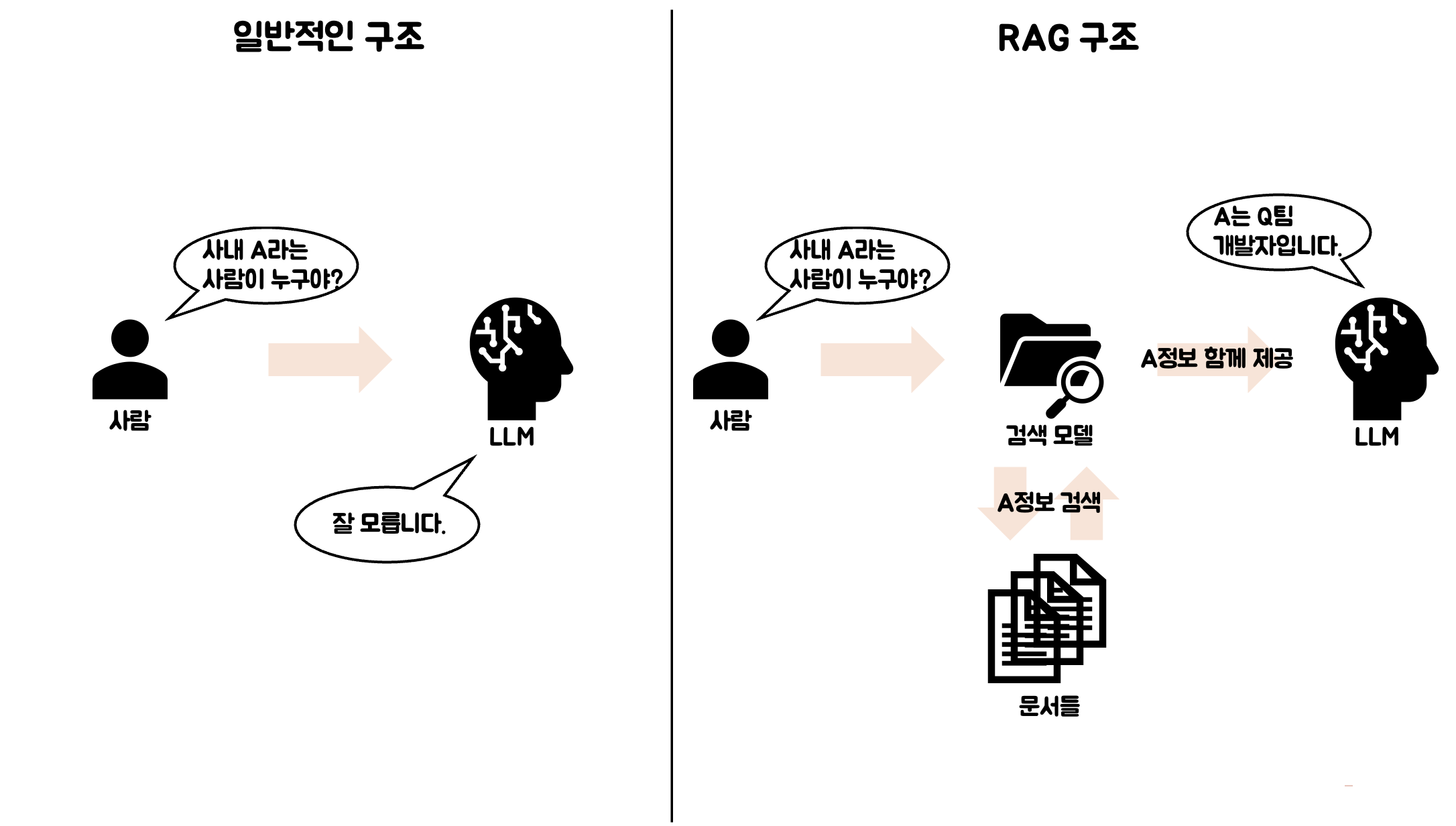
먼저 일반적인 구조를 볼게요. LLM은 별도로 학습하지 않은 이상, 당연히 사내에 있는 A라는 사람의 정보를 모릅니다.
하지만 RAG구조에서는 A에 대한 정보를 검색 모델이 문서에서 한번 검색하고, LLM에게 함께 제공하기 때문에, LLM은 잘 답변해줍니다.
앞에 검색하여 정보를 제공해 주는 로직이 하나 추가된 것이라고 생각하시면 됩니다.
RAG의 필요성
위에서 RAG가 뭔지에 대해 설명을 드렸는데요.
"그냥 LLM 다시 학습시키면 되는거 아님?" 생각이 드실 수 있어요.
물론 맞는 말입니다. 돈과 시간만 많으면 사실 LLM을 재학습 시키는 것이 가장 편한 방법이긴 하죠.
하지만 웬만한 기업에서도 매번 학습시키기에는 부담이 되는 것은 사실입니다.
학습을 한다고 하더라도 LLM에서 자주 나타나는 할루시네이션이 나타날 가능성도 있습니다.
따라서 보다 적은 비용으로 정확한 정보를 답변하기 위해 RAG구조를 사용합니다.
RAG의 구조
RAG가 뭐고, 왜 필요한지 알았으니 이제 자세한 구조에 대해서 알아볼까요?
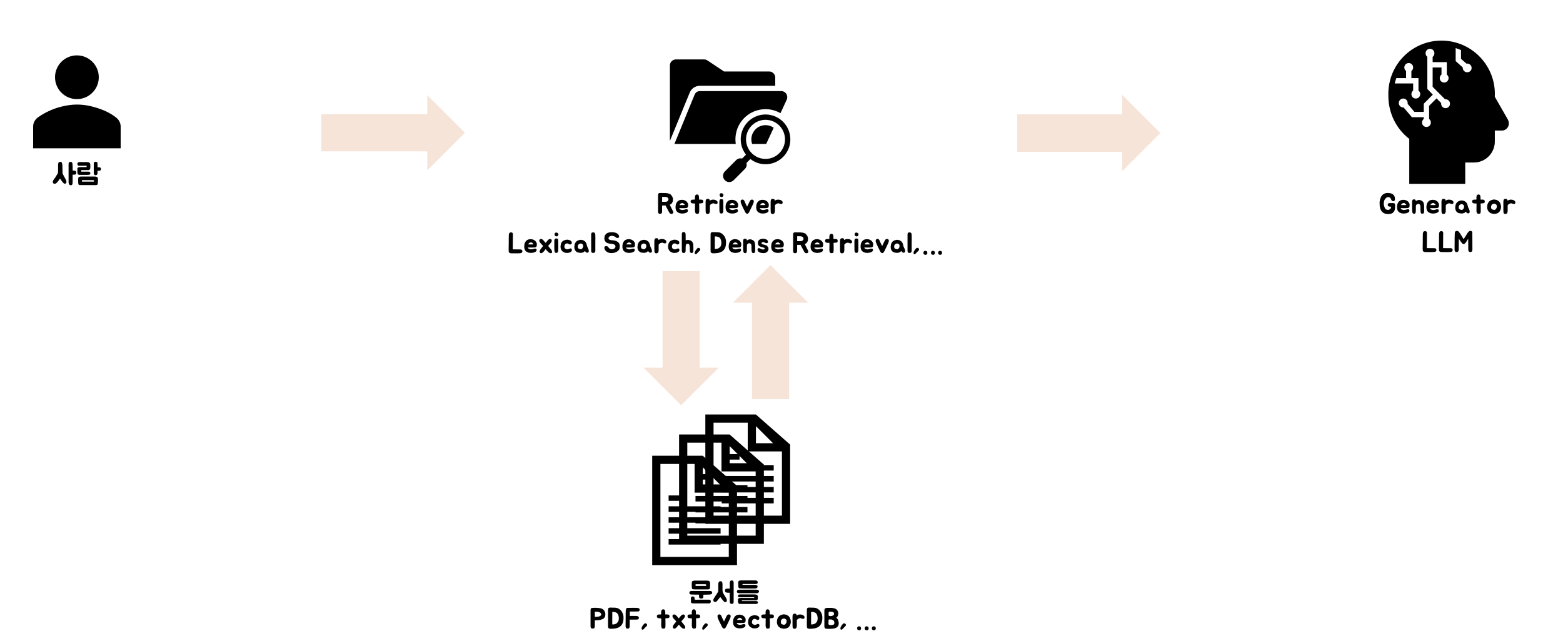
RAG는 크게 문서를 검색하는 Retriever, 답변을 생성하는 Generator로 나뉘어져 있습니다.
Retriever
- "검색기" 역할을 하는 부분입니다.
- 입력받은 질문과 가장 관련 깊은 문서를 찾아줍니다.
- 방법으로는 Lexical, Dense, Hybrid Search가 있습니다.
- 문서는 다양한 형태가 될 수 있습니다.
Generator
- 일반적으로 우리가 알고있는 LLM(GPT, LLama 등)을 뜻합니다.
- Retriever로 부터 받은 정보를 바탕으로 답변을 생성합니다.
간단한 코드 예시(Langchain사용)
Langchain은 LLM을 쉽게 다룰 수 있게 도와주는 파이썬 라이브러리입니다.
Langchain으로도 아주 쉽게 RAG를 구현하실 수 있습니다.
코드가 엄청 간단하죠?
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
# 1. 문서 로드 및 분할
loader = TextLoader("example.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(documents)
# 2. 문서 임베딩 및 벡터 저장 (FAISS 사용)
embedding = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embedding)
# 3. 검색 + 생성 체인 구성
retriever = db.as_retriever()
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
# 4. 질문하고 답 받기!
query = "이 문서의 핵심 내용이 뭐야?"
result = qa.run(query)
print(result)
여기서 등장하는 FAISS는 벡터 DB인데요. 사용 방법은 아래 포스팅에 자세히 적어두었습니다.
물론 Langchain 사용법과는 살짝 다르긴 하지만, 기본적인 동작 과정이 궁금하시면 참고해주세요!
대용량 데이터의 유사도 검색 라이브러리 faiss 사용하기
faiss faiss는 대용량의 데이터 간의 유사도를 빠르게 계산해주는 유사도 검색 라이브러리입니다. 예를 들어 유사한 단어를 찾고 싶다! 하시면 미리 임베딩된 단어들로 "인덱스"를 생성해 주시고, "
jaeyoon-95.tistory.com
이번 포스팅에서는 RAG 기본 개념에 대해서 알아봤는데요.
점점 더 심화 과정을 설명할 예정이니, 관심있으신 분들은 봐주시면 좋을 것 같아요!
읽어주셔서 감사합니다:)
'인공지능공부 > LLM' 카테고리의 다른 글
| RAG Retrieval 단계 Langchain Document loaders 종류 알아보기 (0) | 2025.04.07 |
|---|---|
| ChatGPT 프롬프트 엔지니어링 잘 하는 방법 (1) | 2025.03.26 |
최근 ChatGPT의 등장으로 LLM에 대한 관심이 커지고 있습니다.
하지만 써보신 분들은 아시겠지만, 분명히 LLM도 한계점이 존재합니다.
예를 들어,
최신 정보 반영이 안되어 있다거나,
특정 기업 내에서 쓰는 비밀 문서 등
ChatGPT가 답변할 수 없는 부분도 있습니다.
그렇다면 이 정보를 넣기 위해 큰 모델을 다시 학습시켜야할까요?
아뇨! 꼭 그럴 필요는 없습니다.
관련된 문서를 프롬프트로 같이 넣어줌으로써 ChatGPT가 이를 이해하고, 답변해 줄 수 있습니다.
이것이 바로 RAG의 개념입니다.
ChatGPT에게 관련 문서를 던져주면서 "이게 관련 정보니까 내가 묻는말에 답해!"라고 하는 것과 같습니다.
그럼 이번 포스팅에서 더 자세히 알아볼게요!
더 나아가 실습까지 할 예정이니 끝까지 봐주시면 더 좋겠습니다.
RAG란?
RAG는 Retrieval Augmented Generation이라는 이름에서부터 알 수 있듯이, 관련된 정보를 검색하여 먼저 찾고, 이를 LLM에 같이 넣어 최종 답변을 생성하는 하나의 파이프라인입니다. 간단히 말씀드리자면, 검색 기반의 생성이라고 할 수 있습니다.
더 이해하시기 쉽게 플로우를 그려드릴게요!
먼저 일반적인 구조를 볼게요. LLM은 별도로 학습하지 않은 이상, 당연히 사내에 있는 A라는 사람의 정보를 모릅니다.
하지만 RAG구조에서는 A에 대한 정보를 검색 모델이 문서에서 한번 검색하고, LLM에게 함께 제공하기 때문에, LLM은 잘 답변해줍니다.
앞에 검색하여 정보를 제공해 주는 로직이 하나 추가된 것이라고 생각하시면 됩니다.
RAG의 필요성
위에서 RAG가 뭔지에 대해 설명을 드렸는데요.
"그냥 LLM 다시 학습시키면 되는거 아님?" 생각이 드실 수 있어요.
물론 맞는 말입니다. 돈과 시간만 많으면 사실 LLM을 재학습 시키는 것이 가장 편한 방법이긴 하죠.
하지만 웬만한 기업에서도 매번 학습시키기에는 부담이 되는 것은 사실입니다.
학습을 한다고 하더라도 LLM에서 자주 나타나는 할루시네이션이 나타날 가능성도 있습니다.
따라서 보다 적은 비용으로 정확한 정보를 답변하기 위해 RAG구조를 사용합니다.
RAG의 구조
RAG가 뭐고, 왜 필요한지 알았으니 이제 자세한 구조에 대해서 알아볼까요?
RAG는 크게 문서를 검색하는 Retriever, 답변을 생성하는 Generator로 나뉘어져 있습니다.
Retriever
- "검색기" 역할을 하는 부분입니다.
- 입력받은 질문과 가장 관련 깊은 문서를 찾아줍니다.
- 방법으로는 Lexical, Dense, Hybrid Search가 있습니다.
- 문서는 다양한 형태가 될 수 있습니다.
Generator
- 일반적으로 우리가 알고있는 LLM(GPT, LLama 등)을 뜻합니다.
- Retriever로 부터 받은 정보를 바탕으로 답변을 생성합니다.
간단한 코드 예시(Langchain사용)
Langchain은 LLM을 쉽게 다룰 수 있게 도와주는 파이썬 라이브러리입니다.
Langchain으로도 아주 쉽게 RAG를 구현하실 수 있습니다.
코드가 엄청 간단하죠?
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
from langchain.text_splitter import CharacterTextSplitter
from langchain.document_loaders import TextLoader
# 1. 문서 로드 및 분할
loader = TextLoader("example.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
docs = text_splitter.split_documents(documents)
# 2. 문서 임베딩 및 벡터 저장 (FAISS 사용)
embedding = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embedding)
# 3. 검색 + 생성 체인 구성
retriever = db.as_retriever()
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
qa = RetrievalQA.from_chain_type(llm=llm, retriever=retriever)
# 4. 질문하고 답 받기!
query = "이 문서의 핵심 내용이 뭐야?"
result = qa.run(query)
print(result)
여기서 등장하는 FAISS는 벡터 DB인데요. 사용 방법은 아래 포스팅에 자세히 적어두었습니다.
물론 Langchain 사용법과는 살짝 다르긴 하지만, 기본적인 동작 과정이 궁금하시면 참고해주세요!
대용량 데이터의 유사도 검색 라이브러리 faiss 사용하기
faiss faiss는 대용량의 데이터 간의 유사도를 빠르게 계산해주는 유사도 검색 라이브러리입니다. 예를 들어 유사한 단어를 찾고 싶다! 하시면 미리 임베딩된 단어들로 "인덱스"를 생성해 주시고, "
jaeyoon-95.tistory.com
이번 포스팅에서는 RAG 기본 개념에 대해서 알아봤는데요.
점점 더 심화 과정을 설명할 예정이니, 관심있으신 분들은 봐주시면 좋을 것 같아요!
읽어주셔서 감사합니다:)
'인공지능공부 > LLM' 카테고리의 다른 글
| RAG Retrieval 단계 Langchain Document loaders 종류 알아보기 (0) | 2025.04.07 |
|---|---|
| ChatGPT 프롬프트 엔지니어링 잘 하는 방법 (1) | 2025.03.26 |